Deterministic fake data for PostgreSQL with ripoff
If you maintain a web application and like to test locally, you probably have some amount of fake data (stuff that mimics your real production database). In my open source repos I’ve used it to provide people a starting point on install, and at my work we use it to make it feel like we’re real customers of our product.
Fake data doesn’t seem like the hardest problem in the world to solve, but it’s surprisingly annoying to maintain at scale. Multiple teams maintaining their own subsets of fake data, all relying on centralized IDs to reference, it can start to feel really messy after a while!
I’ve used a lot of flavors of fake data generators, ranging from fully randomized fuzzers that are guaranteed to fill your database with "something", to bespoke application specific “entity factories” that feel a bit more like your normal code. Randomization is cool but doesn’t usually represent the shape of data users see. I also find doing this in the same language I write the app in to feel strange, and in my experience you eventually end up with two APIs - one for the normal paths to insert data and one for the hacky paths to insert fake data.
What I really wanted was machine food for human consumption - a set of human readable instructions to insert data into the database that’s usable for testing and agnostic to my language/framework.
With all this in mind I created ripoff, a deterministic fake data generator for PostgreSQL written in Go.
ripoff lets you write fake data in one or more YAML files (ripoffs). ripoffs contain rows keyed by unique identifiers in the format `table:func(seed)`, where each row is a map of columns to their values.
To jump into an example, with this schema:
CREATE TABLE avatars (
id UUID NOT NULL PRIMARY KEY,
url TEXT NOT NULL
);
CREATE TABLE users (
id UUID NOT NULL PRIMARY KEY,
avatar_id UUID NOT NULL REFERENCES avatars,
email TEXT NOT NULL
);The ripoff may look like:
rows:
users:uuid(samuel):
email: email(samuel)
avatar_id: avatars:uuid(samuelAvatar)
avatars:uuid(samuelAvatar):
url: samuel.pngI can be objective and say that this format isn’t immediately grokkable, so here’s some footnotes about what’s going on:
- The row key `users:uuid(samuel)` says “This is a row in the users table, identified with a UUID generated pseudorandomly using the seed “samuel”.
- The line `email: email(samuel)` generates a random email address with the seed “samuel”. A number of generation functions are available via gofakeit.
- The line `avatar_id: avatars:uuid(samuelAvatar)` informs ripoff that this is a foreign key to `avatars`, which helps it insert rows in the correct order.
- You’ll notice no `id` columns are defined - ripoff is schema-aware and for single-column primary keys it will use the row key (in this case the generated UUID). This is only really in ripoff for UX reasons and is optional if the implicit behavior is unclear.
When ripoff runs, it concatenates all the rows from all your ripoffs (assembling a total ripoff, as it's known internally), builds a dependency graph based on the use of row keys, sorts it so that rows are inserted in order, then builds queries for each row.
Here's a probably not-needed diagram of the process:
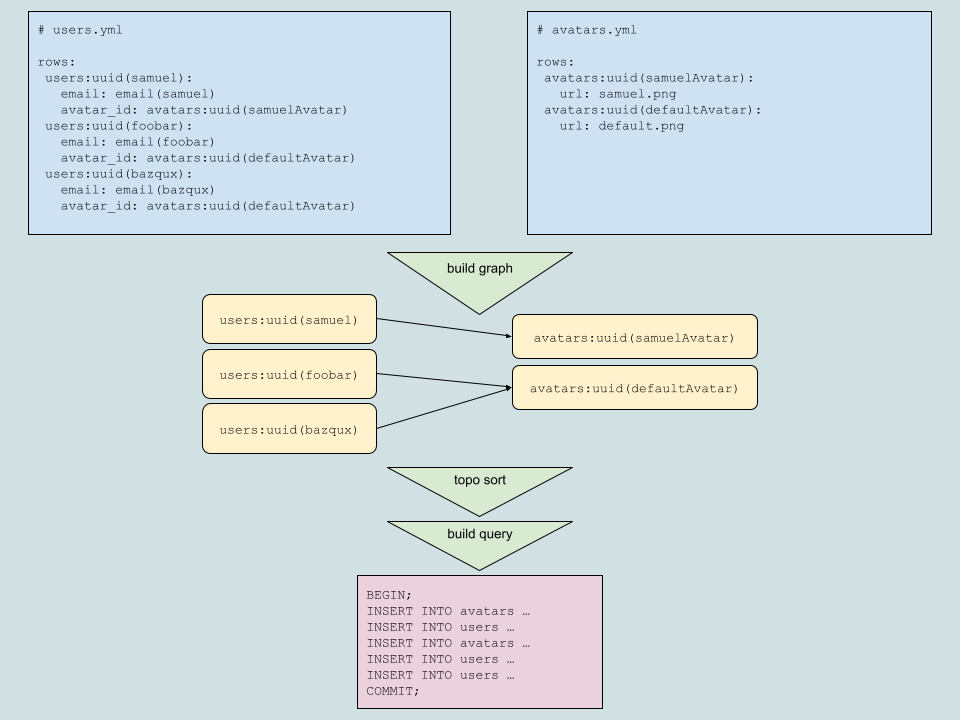
The queries ripoff builds are based literally on what rows you provided, it doesn’t use a DSL and doesn’t check that your provided tables and columns exist in the schema. All provided values besides `null` are treated as strings.
For example, the “avatars” row above may generate a query like:
INSERT INTO "avatars" ("url","id")
VALUES ('samuel.png','d90acc71-dd76-437d-8f64-e95b29c0914a')
ON CONFLICT ("id")
DO UPDATE SET
"url" = 'samuel.png',
"id" = 'd90acc71-dd76-437d-8f64-e95b29c0914a';You’ll notice this is an upsert - since ripoff doesn’t allow you to generate random data with random seeds, you can make edits to your fake data and safely re-run ripoff to update existing rows. As far as I know this is a fairly unique feature of the project, everywhere I’ve worked before has required a database wipe to re-generate fake data!
Manually defining every row you want to insert for your fake data works for a lot of simple schemas, but for applications where one feature represents many dependent rows it starts to feel lacking. To address this, ripoff rows can be generated using Go templates.
Here’s an example template for a user with an optional avatar:
rows:
# "rowId" is the map key the caller chose (ex: users:...).
{{ .rowId }}:
email: {{ .email }}
avatar_id: avatars:uuid({{ .rowId }}-avatar)
avatars:uuid({{ .rowId }}-avatar):
url: {{ if .avatarUrl }}{{ .avatarUrl }}{{ else }}default.png{{ end }}which can be used like:
rows:
users:uuid(fooBar):
template: template_user.yml
email: [email protected]
users:uuid(bazQux):
template: template_user.yml
email: [email protected]
# When using `template:`, row keys represent template variables,
# not columns.
avatarUrl: foobar.pngI have kind of mixed feelings about this - Go templates are ugly and the story that ripoff is a "simple" way to concat upsert queries kind of falls apart here. However, great news is that templates are totally optional and two of my coworkers using this for side projects don’t use them at all! So if they gross you out and you can live without them, go for it.
For more (sometimes crazy looking) ripoff examples, check out the test fixtures at https://github.com/mortenson/ripoff/tree/main/testdata/import
In my side project (https://awaysync.com), ripoff replaced a gigantic Go file with lots of hardcoded logic and fake data. I use sqlc instead of a query builder, which meant that in many cases fake data required many distinct queries that were never used in the normal app. It was getting weird, even though I had less than ten tables at that point.
I’ve been happy with ripoff so far, but I’ll note that the original intention for the project was to possibly replace “in-framework” fake data generation at my day job. At work we use Haskell and Persistent, which provide strong type safety when constructing queries. Additionally we represent many database types like enums as Haskell sum types, which is just one example of sharing APIs between the real app and our fake data code. While ripoff could have some role there (test fixtures?), it's probably not a fit to replace everything.
That said, there are probably some objective things about ripoff that are cool for anyone looking to migrate:
- It’s fast, or almost certainly faster than doing this in the framework your app lives in
- Since the order of rows don’t matter and you can have any number of ripoffs in one directory, multiple teams can maintain their own fake data without editing the same files
- Inserting data that is otherwise invalid in your app is possible, which is great for representing “historic” inserts (ex: rows that don’t have a value for a forward-not-nullable column)
- You can re-run it without wiping the database
So if you’re curious and want to give it a try, follow the install instructions in the README and let me know what you think!