Static searches with Drupal and Lunr
As a part of my ongoing work on Tome, a Drupal static site generator, I’ve become interested in providing a solution for static searches. If you have a static site there’s typically no backend to do any server side processing, which means that search has to be done on the client or through a third party service. After researching some existing solutions I found Lunr, a JavaScript based search engine that provides a simple API for indexing and searching content. It seemed like Drupal and Lunr would be a great match, so I set out to build an integration.
First, I needed to figure out how to get data from Drupal into Lunr. Existing search modules in Drupal like Search API provide a lot of customization for indexing, but also rely on there being a Drupal backend at runtime. It felt awkward to throw users into the Search API ecosystem with the caveat that most of the functionality they get using core or Solr search would not be available. I eventually landed on using Views, with a custom display, row, and style plugin that output JSON in a very similar way to the “REST export” plugin. Views has so much built in for data transformation, it seemed like a natural fit for this use case and was already accessible to site builders.
The Views plugins I wrote output pages of arrays of objects, where every object property is either a field to index in Lunr or a field to be displayed to end users. A typical setup may index the title and body fields, then have a html field that contains the rendered HTML of an entity view mode. A ref field is automatically added in the format page:index, so that when Lunr returns search results there’s a unique key to use to retrieve the display field.
With the data source figured out, it’s time to index our content. In a simple Lunr setup, the client will load all the source documents, create an index, and then perform a search against that index every time a search session is started. For a simple implementation with few documents this could be acceptable, but since this is all happening on the client it doesn’t scale far. Luckily, Lunr allows indexes to be pre-built and exported to JSON, then loaded in the client without needing the client to load any source documents.
The settings required to configure the indexing behavior needed to be stored somewhere, so I created a custom entity type that is a combination of what would normally be separate server, index, and view entities. This custom entity, “Lunr search”, has a form that looks like this:
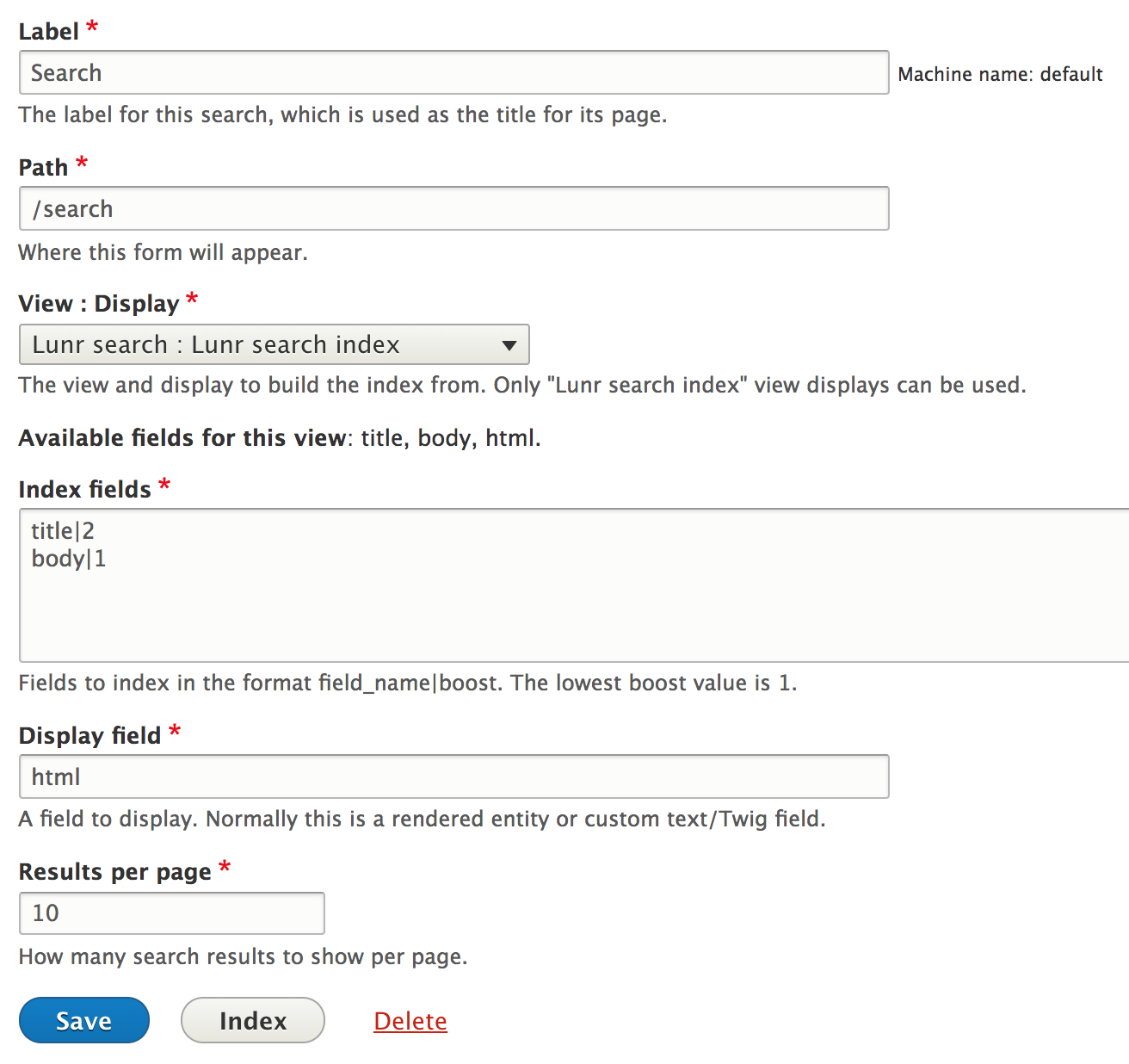
Now that the pieces were in place, it was time to write the real indexing behavior. Indexing currently works like this:
- Indexing is initiated by an administrator in the UI.
- A Lunr Builder instance is created with the settings from the Lunr search entity.
- In JavaScript, AJAX requests are made to the view path to get JSON.
- Every view row is indexed as a Lunr document.
- The configured “Display field” is stored in a separate array of objects, which stores the ref field and the display field.
- When a page is finished, the display document is uploaded to the server.
- Additional requests are made to page through the view.
- When there are no other pages to index, the builder exports JSON that is uploaded to the server.
- If there are any other installed languages, the entire process is repeated for each language. This allows for language specific indexes to be loaded by the client.
If it sounds complicated, it’s because it really is! But having Drupal do this work before hand means clients only have to load the compiled index to start searching.
Speaking of searching…I still had to build a user interface for search. I started simple, having the client fetch the index with AJAX, load it, then allow searching through a JavaScript-enabled form. When a user entered a search query, the index would return results which would then be used to perform additional AJAX requests necessary to get those display documents, which contained the user-facing search result HTML. This was functional, but it turns out replicating the search experience Drupal users are used to isn’t easy. I had to allow search via query parameter, get paging working, show the typical Drupal throbber, and make sure that the window history was updated so back and forward buttons continued to work. All this probably seems trivial to a frontend developer but I’ve always considered myself more backend-aligned, so it was quite the learning experience for me. After a lot of time tweaking, I had something that felt and looked like a typical Drupal search - the main difference being that everything was happening solely in the client, so it was super fast with small indexes.
But what about big indexes? A few people had asked me about performance and scale, and all my tests in the 100-1000 document range had worked great, but I wanted to see what practical limits Lunr had. I spun up a site and created 10,000 nodes, which were able to index fine, but after the client downloaded the huge 35mb index the main thread would noticeably lock up for a few seconds. Once loaded searches were surprisingly fast, but the main performance issue was that first interaction.
The only way I could think of to get around this was to use web workers, which allow JavaScript code to run in another thread. By using workers, I could do the index load and all searching in another thread and not block user interactions in the main thread. This also oddly enabled the non-worker code to not use Lunr’s APIs, and instead just ask the worker to perform searches however it seemed fit. It was a really big rewrite, but it worked out in the end. There is probably still a limit to what this Lunr integration can handle, but the search experience with large indexes isn’t too bad.
One last piece of the usability puzzle was facets, which are popular in many Drupal search implementations. Lunr does provide the ability to search by multiple fields, so I was tempted to just tell users to use JavaScript and figure it out on their own, but I ended up proving out the integration myself and fixing many bugs in the process. This was also when I found the first, and so far only, part of Lunr that was lacking - the ability to use complex conditions and condition groups. When you search with Lunr, you might enter a query like black cat, which would translate to something like Any field contains black OR cat when parsed. To do a field search, you write something like black cat type:shorthair, which will also end up in an OR. This doesn’t quite work because users expect facets to reduce search results, and if I checked “shorthair” in a facet I would expect only shorthair results. You can use a “+” symbol to make a term required, but black cat +type:shorthair could end up with shorthair animals that aren’t black or cats. This was a big deal to me and I wanted to fix it, so I ended up making two queries, one for the search terms (black cat), and another for all the fields (+type:shorthair), then finding the intersection of both search results. Enabling users to add facets with a bit of custom code was worthwhile, even with the last minute hair pulling.
With all the deep details out of the way, here’s how searching currently works:
- The user loads the Lunr search page.
- A web worker is created.
- The web worker loads the Lunr library, and makes an AJAX request for the index file and loads it.
- The user enters a search query, or a query string is provided.
- The window history is updated as well as the URL.
- A message is sent to the web worker.
- The worker uses the Lunr to perform the query.
- If any field searches (aka facets) are present, another query is performed and the results are merged.
- The worker sends a message back to the client with the search results, which are just an array of reference (ref) IDs.
- The client makes additional AJAX calls based on the results to get the user-facing HTML from the display document JSON. Typically this is less than one call per result as many results may be in the same document.
- The results are displayed to the client, along with pagers if needed.
Phew! I feel like writing all this out makes the Drupal integration seem really complex, but I think that’s just because I’ve tried to provide something that’s actually viable as a replacement for core search. Running a Drupal static site means losing the backend, and it’s easy to take out of the box features like search for granted. I’m just glad that this project worked out and is usable - now there’s an actual answer for “How do you do static search?” that doesn’t involve me hand-waving!
In conclusion, the Drupal Lunr integration is ready for testing and use - the project is called “Lunr search” and can be downloaded here. There are no composer dependencies and a default search is provided out of the box, so if you enable it and kick off indexing at "/admin/config/lunr_search/default/index", you should be able to do a test search at /search. I know I’ve talked a bit about static sites in this post, but I think the Lunr module is useful for all sorts of sites. Having your search be static means less uncacheable hits to your backend, and potentially a faster experience for users, so please try it out if you’re interested!